
Sentinel Code Analyze
sentinel-go
背景
之前团队在服务治理项目过程中引入了司内稳定性相关的组件,其中也包含了流量控制、熔断降级等稳定性相关的能力,但我一直也没有时间来深挖各模块的实现细节。趁最近有空,看了下阿里开源版本的稳定性组件sentinel实现,整体感觉代码结构清晰,在并发控制、性能优化细节上也做了不少工作,于是花时间仔细阅读了下部分代码,并输出笔记一篇。
另外写文章之前发现sentinel的官方文档非常细致,包括功能使用以及原理介绍,于是直接copy了部分,并根据最新代码做了修正。最后补充了流量控制的代码分析,其他模块原理也类似,时间有限就没有逐一阅读了。
Sentinel介绍:Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
流量控制
任意时间到来的请求往往是随机不可控的,而系统的处理能力是有限的。我们需要根据系统的处理能力对流量进行控制。Sentinel 作为一个调配器,可以根据需要把随机的请求调整成合适的形状。
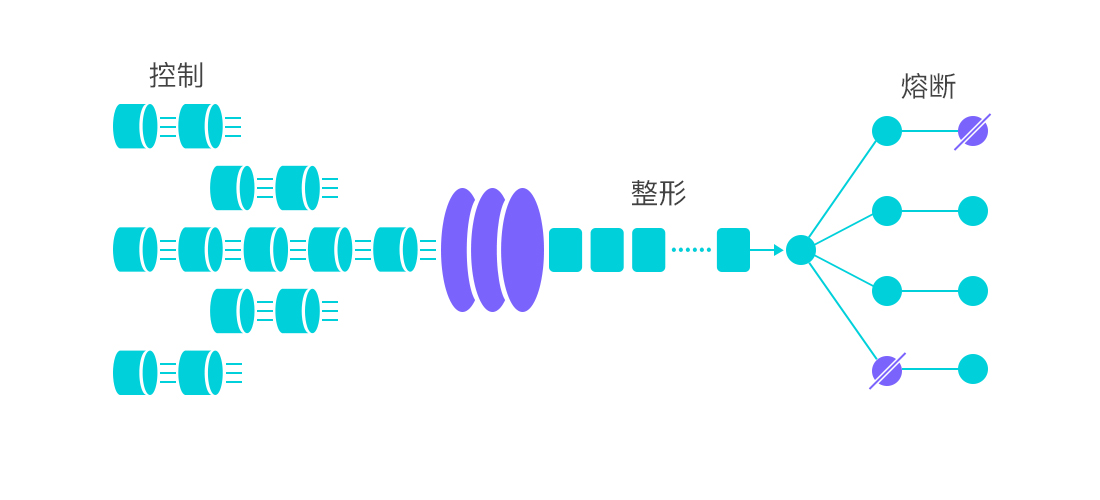
流量控制有以下几个角度:
- 资源的调用关系,例如资源的调用链路,资源和资源之间的关系;
- 运行指标,例如 QPS、线程池、系统负载等;
- 控制的效果,例如直接限流、冷启动、排队等。
Sentinel 的设计理念是让您自由选择控制的角度,并进行灵活组合,从而达到想要的效果。
熔断降级
Sentinel 和 Hystrix 的原则是一致的: 当调用链路中某个资源出现不稳定,例如,表现为 timeout,异常比例升高的时候,则对这个资源的调用进行限制,并让请求快速失败,避免影响到其它的资源,最终产生雪崩的效果。
在限制的手段上,Sentinel 和 Hystrix 采取了完全不一样的方法。
Hystrix 通过线程池的方式,来对依赖(在我们的概念中对应资源)进行了隔离。这样做的好处是资源和资源之间做到了最彻底的隔离。缺点是除了增加了线程切换的成本,还需要预先给各个资源做线程池大小的分配。
Sentinel 对这个问题采取了两种手段:
- 通过并发线程数进行限制
和资源池隔离的方法不同,Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的影响。这样不但没有线程切换的损耗,也不需要您预先分配线程池的大小。当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接收请求。
- 通过响应时间对资源进行降级
除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降级不稳定的资源。当依赖的资源出现响应时间过长后,所有对该资源的访问都会被直接拒绝,直到过了指定的时间窗口之后才重新恢复。
系统负载保护
Sentinel 同时提供系统维度的自适应保护能力。防止雪崩,是系统防护中重要的一环。当系统负载较高的时候,如果还持续让请求进入,可能会导致系统崩溃,无法响应。在集群环境下,网络负载均衡会把本应这台机器承载的流量转发到其它的机器上去。如果这个时候其它的机器也处在一个边缘状态的时候,这个增加的流量就会导致这台机器也崩溃,最后导致整个集群不可用。
针对这个情况,Sentinel 提供了对应的保护机制,让系统的入口流量和系统的负载达到一个平衡,保证系统在能力范围之内处理最多的请求。
更多的能力项介绍详见《官方文档》。
基本用法
用户接入使用 Sentinel Go (后文均用 Sentinel 表示 Sentinel Go) 主要需要需要以下几步:
- 对 Sentinel 的运行环境进行相关配置并初始化。API 接口使用细节可以参考:配置方式
- 埋点(定义资源),该步骤主要是确定系统中有哪些资源需要防护,资源定义可参考:新手指南
- 配置规则,该步骤主要是为每个资源都配置具体的规则,规则的配置可参考:新手指南 以及各个模块的使用文档。
- 编写资源防护的入口和出口代码。释放方式可参考:新手指南
配置
典型配置
version: "v1" |
配置规则
定义各种资源以及流量控制阈值及触发动作。支持两种规则配置方式:
1、hardcode编码:使用LoadRules手动加载。
_, err = flow.LoadRules([]*flow.Rule{ |
2、动态数据源
Sentinel 提供动态数据源接口进行扩展,用户可以通过动态文件、etcd、consul、nacos 等配置中心来动态地配置规则。详情请参考动态数据源使用文档。
埋点(资源访问)
使用 Sentinel 的 Entry API 将业务逻辑封装起来,这一步称为“埋点”。每个埋点都有一个资源名称(resource),代表触发了这个资源的调用或访问。
// EntryOptions represents the options of a Sentinel resource entry. |
资源防护的入口和出口代码
对请求被拦截和通过时的处理。
原理
Sentinel 的主要工作机制如下:
- 对主流框架提供适配或者显示的 API,来定义需要保护的资源,并提供设施对资源进行实时统计和调用链路分析。
- 根据预设的规则,结合对资源的实时统计信息,对流量进行控制。同时,Sentinel 提供开放的接口,方便您定义及改变规则。
- Sentinel 提供实时的监控系统,方便您快速了解目前系统的状态。
流量控制
流量控制(flow control),其原理是监控资源(Resource)的统计指标,然后根据 token 计算策略来计算资源的可用 token(也就是阈值),然后根据流量控制策略对请求进行控制,避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。
Sentinel 通过定义流控规则来实现对 Resource 的流量控制。在 Sentinel 内部会在加载流控规则时候将每个 flow.Rule 都会被转换成流量控制器(TrafficShapingController)。 每个流量控制器实例都会有自己独立的统计结构,这里统计结构是一个滑动窗口。Sentinel 内部会尽可能复用 Resource 级别的全局滑动窗口,如果流控规则的统计设置没法复用Resource的全局统计结构,那么Sentinel会为流量控制器创建一个全新的私有的滑动窗口,然后通过 flow.StandaloneStatSlot 这个统计Slot来维护统计指标。
规则定义
type Rule struct { |
StatIntervalInMs 和 Threshold 这两个字段,这两个字段决定了流量控制器的灵敏度。以 Direct + Reject 的流控策略为例,流量控制器的行为就是在 StatIntervalInMs 周期内,允许的最大请求数量是Threshold。比如如果 StatIntervalInMs 是 10000,Threshold 是10000,那么流量控制器的行为就是控制该资源10s内运行最多10000次访问。
流量控制策略
Sentinel 的流量控制策略由规则中的 TokenCalculateStrategy 和 ControlBehavior 两个字段决定。TokenCalculateStrategy 表示流量控制器的Token计算方式,目前Sentinel支持3种:
- Direct表示直接使用规则中的
Threshold表示当前统计周期内的最大Token数量。 - WarmUp表示通过预热的方式计算当前统计周期内的最大Token数量,预热的计算方式会根据规则中的字段
WarmUpPeriodSec和WarmUpColdFactor来决定预热的曲线。 - MemoryAdaptive表示根据当前内存大小以及最大、小内存阈值(
memLowWaterMarkBytes和memLowWaterMarkBytes)的关系计算当前周期内的最大Token数,使其范围位于[lowMemUsageThreshold,highMemUsageThreshold]之间。
WarmUp 方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过”冷启动”,让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。这块设计和 Java 类似,可以参考限流-冷启动文档

字段 ControlBehavior 表示表示流量控制器的控制行为,目前 Sentinel 支持两种控制行为:
- Reject:表示如果当前统计周期内,统计结构统计的请求数超过了阈值,就直接拒绝。
- Throttling:表示匀速排队的统计策略。它的中心思想是,以固定的间隔时间让请求通过。当请求到来的时候,如果当前请求距离上个通过的请求通过的时间间隔不小于预设值,则让当前请求通过;否则,计算当前请求的预期通过时间,如果该请求的预期通过时间小于规则预设的 timeout 时间,则该请求会等待直到预设时间到来通过(排队等待处理);若预期的通过时间超出最大排队时长,则直接拒接这个请求。
匀速排队方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。这种方式主要用于处理间隔性突发的流量,例如消息队列。
流量控制器的统计结构
每个流量控制器实例都会有自己独立的统计结构。流量控制器的统计结构由规则中的 StatIntervalInMs 字段设置,StatIntervalInMs表示统计结构的统计周期。Sentinel 默认会为每个Resource创建一个全局的滑动窗口统计结构,这个全局的统计结构默认是一个间隔为10s,20个格子的滑动窗口,也就是每个统计窗口长度是500ms。
流量控制器实例会尽可能复用这个Resource级别的全局统计结构,复用逻辑原则是:优先复用Resource级别的全局统计结构,如果不可复用,就重新创建一个独立的滑动窗口统计结构(BucketLeapArray),具体的逻辑细节如下:
- 如果
StatIntervalInMs大于全局滑动窗口的间隔(默认10s),那么将不可复用全局统计结构。Sentinel会给流量控制器创建一个长度是StatIntervalInMs,格子数是1的全新统计结构,这个全新的统计结构由Sentinel内部的StandaloneStatSlot来维护统计。 - 如果
StatIntervalInMs小于全局滑动窗口的窗口长度(默认是500ms), 那么将不可复用全局统计结构。Sentinel会给流量控制器创建一个长度是StatIntervalInMs,格子数是1的全新统计结构,这个全新的统计结构由Sentinel内部的StandaloneStatSlot来维护统计。 - 如果
StatIntervalInMs在集合[全局滑动窗口的窗口长度,全局滑动窗口的间隔]之间,首先需要计算格子数:如果StatIntervalInMs可以被全局滑动窗口的窗口长度(默认是500ms)整除,那么格子数就为StatIntervalInMs/GlobalStatisticBucketLengthInMs,如果不可整除,格子数是1。然后会调用core/base/CheckValidityForReuseStatistic函数来判断当前统计结构间隔和格子数是否可以复用全局统计结构。如果可以复用,就会基于resource级别的全局统计结构ResourceNode创建SlidingWindow,SlidingWindow是一个虚拟结构,SlidingWindow只可读,而且读的数据是通过聚合ResourceNode数据得到的。如果不可复用,就使用统计结构间隔和格子数创建全新的滑动窗口(BucketLeapArray)。
CheckValidityForReuseStatistic函数参考:https://github.com/alibaba/sentinel-golang/blob/master/core/base/stat.go#func CheckValidityForReuseStatistic
基于规则创建统计结构的逻辑参考:https://github.com/alibaba/sentinel-golang/blob/master/core/flow/rule_manager.go#func generateStatFor
常见场景的规则配置
- 基于QPS对某个资源限流:常规场景,StatIntervalInMs为1s时Threshold所配置的值也就是QPS的阈值。
- 基于一定统计间隔时间来控制总的请求数:允许在一定统计周期内控制请求的总量。但是这种流控配置对于脉冲类型的流量抵抗力很弱,有极大潜在风险压垮系统。
- 毫秒级别流控:建议
StatIntervalInMs的配置在毫秒级别,除非特殊场景,建议配置的值为100ms的倍数。这种配置能够很好的应对脉冲流量,保障系统稳定性。 - 脉冲流量无损:前面第三点场景,如果既想控制流量曲线,又想无损,一般做法是通过匀速排队的控制策略,平滑掉流量。
- 基于调用关系的流量控制:当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢。
熔断降级
熔断器有三种状态:
- Closed 状态:也是初始状态,该状态下,熔断器会保持闭合,对资源的访问直接通过熔断器的检查。
- Open 状态:断开状态,熔断器处于开启状态,对资源的访问会被切断。
- Half-Open 状态:半开状态,该状态下除了探测流量,其余对资源的访问也会被切断。探测流量指熔断器处于半开状态时,会周期性的允许一定数目的探测请求通过,如果探测请求能够正常的返回,代表探测成功,此时熔断器会重置状态到 Closed 状态,结束熔断;如果探测失败,则回滚到 Open 状态。
Sentinel 提供了监听器去监听熔断器状态机的三种状态的转换,方便用户去自定义扩展:
// StateChangeListener listens on the circuit breaker state change event. |
熔断器的设计
衡量下游服务质量时候,场景的指标就是RT(response time)、异常数量以及异常比例等等。Sentinel 的熔断器支持三种熔断策略:慢调用比例熔断、异常比例熔断以及异常数量熔断。
用户通过设置熔断规则(Rule)来给资源添加熔断器。Sentinel会将每一个熔断规则转换成对应的熔断器,熔断器对用户是不可见的。Sentinel 的每个熔断器都会有自己独立的统计结构。
熔断器的整体检查逻辑可以用几点来精简概括:
- 基于熔断器的状态机来判断对资源是否可以访问;
- 对不可访问的资源会有探测机制,探测机制保障了对资源访问的弹性恢复;
- 熔断器会在对资源访问的完成态去更新统计,然后基于熔断规则更新熔断器状态机。
熔断策略
Sentinel 熔断器的三种熔断策略都支持静默期 (规则中通过MinRequestAmount字段表示)来降低误判的可能性。静默期是指一个最小的静默请求数,在一个统计周期内,如果对资源的请求数小于设置的静默数,那么熔断器将不会基于其统计值去更改熔断器的状态。
Sentinel 支持以下几种熔断策略:
- 慢调用比例策略 (SlowRequestRatio):Sentinel 的熔断器不在静默期,并且慢调用的比例大于设置的阈值,则接下来的熔断周期内对资源的访问会自动地被熔断。该策略下需要设置允许的调用 RT 临界值(即最大的响应时间),对该资源访问的响应时间大于该阈值则统计为慢调用。
- 错误比例策略 (ErrorRatio):Sentinel 的熔断器不在静默期,并且在统计周期内资源请求访问异常的比例大于设定的阈值,则接下来的熔断周期内对资源的访问会自动地被熔断。
- 错误计数策略 (ErrorCount):Sentinel 的熔断器不在静默期,并且在统计周期内资源请求访问异常数大于设定的阈值,则接下来的熔断周期内对资源的访问会自动地被熔断。
注意:这里的错误比例熔断和错误计数熔断指的业务返回错误的比例或则计数。也就是说,如果规则指定熔断器策略采用错误比例或则错误计数,那么为了统计错误比例或错误计数,需要调用API: api.TraceError(entry, err) 埋点每个请求的业务异常。
熔断降级规则定义
// Rule encompasses the fields of circuit breaking rule. |
源码分析
目录结构
├── api |
如上,几个核心功能(流量控制、熔断降级、并发隔离等)都是按目录分别存放,每个目录整体结构类似,可以分为规则解析、行为控制以及slot检查逻辑三部分。最后使用责任链模式,将各个模块在Entry入口处使用SlotChain串联起来遍历调用。
此处仅分析流量控制模块相关的流程及数据结构,包括部分公共模块。
sentinel初始化
入口:InitWithConfigFile、InitDefault
目的:从配置文件读取、解析配置,并执行初始化动作
流程:
- yaml配置解析,格式见上方的典型配置。
- 校验字段有效性,重点关注stat中的几个流量控制器统计相关的参数。
- 从env中读取配置,目的是为了支持通过环境变量控制AppName、AppType、LogPath等参数。
- 初始化日志:基于标准库log.Logger封装日志lib。参考logging/下实现。
- 核心公共component(goroutine协程)初始化,用于辅助后面的流控逻辑。
- 日志定时flush任务开启(配置开关)。
- 启动三个系统指标(load、cpu、mem)的收集定时器,定期采集并(原子操作)存储到内存。方案使用gopsutil实现,cpu、mem数据会用于Prometheus上报,cpu、load数据会用作规则校验。(AdaptiveSlot.doCheckRule)
- 开启时间更新定时器(UseCacheTime),降低频繁的时间采集调用对系统的影响。大流量系统建议开启。
- 开启Prometheus export服务(http server),会影响来自Prometheus服务端的定期收集。详见metric_exporter.HTTPHandler实现。
流量控制规则初始化
入口:flow.LoadRule
目的:将每个资源的规则转列表换为流量控制器的列表,用于后续的资源访问(埋点)。
流程:
rule_manager:维护全局的规则map,结构 map[string][]*Rule,即规则名 → 规则列表的映射。
规则加载LoadRules:
- 每次LoadRules时会从使用新的规则替换之前已有的全部资源+规则,非法的Rule会被过滤。或者使用LoadRulesOfResource替换某个资源的全部规则。为何Resouce不能动态新增规则?
- 协程安全:使用了atomic允许多个goroutine并行Load
- 资源的规则列表*[]Rule数据会转换为流量控制器**[]TrafficShapingController*列表,用于执行真实的流量控制。
- 全局对象tcMap维护资源到TrafficShapingController列表的映射,供后续查询等处理。
- 全局对象currentRules记录规则的列表。如果重复加载相同规则集不会做任何初始化动作。
重点逻辑为构建流量控制器列表,在分析其逻辑之前,先看下流量控制器TrafficShapingController的具体定义。
// TrafficSharpingController代码了单条Rule对应流量计算 + 流量控制行为 |
流量控制器的作用就是根据当前流量数据,与阈值计算器返回的当前阈值比较,然后根据比较结果以及行为控制器的配置,来告诉调用方采取何种动作(放过、Block或者排队)。构建流量控制器的行为就是将原始的Rule转换为流量控制器的过程(buildResourceTrafficShapingController):
- 每条Rule对应一条单独的流量控制器,即使同一资源存在多条重复规则,也会生成不同的Controller各自计算。
- 构建过程中如果之前已经有可复用的Controller了会被复用(复用条件:规则条件完全一致或者部分一致,见isStatReusable()) —— 复用有条件,所以服务在运行过程中规则有变更时需要考虑是否可能存在断时间控制未生效的情况。
- 构建TrafficShapingController,重点是计算器flowCalculator和控制器flowChecker的选择方式,会依赖规则的TokenCalculateStrategy、ControlBehavior。目前实现了3种计算器和2种行为控制器。
// 阈值(Threshold)计算 |
三种阈值计算器:
- DirectTrafficShapingCalculator:直接使用固定值threshold作为阈值。
- TrafficShapingCalculator:使用冷启动算法计算当前阈值,算法参考《官方说明》。使用系统启动需要预热的场景,避免短时间的流量高峰将系统冲垮。
- MemoryAdaptiveTrafficShapingCalculator:根据当前服务内存占用以及相关配置,动态计算使其处于[LowMemUsageThreshold, HighMemUsageThreshold]之间。当内存位于阈值之间时按比例取值。注意这里要配置好Rule中内存相关的四个参数值。
两种行为控制器:
- RejectTrafficShapingChecker:如果当前token计数大于计算器返回的阈值,直接返回rejectTokenResult(state: ResultStatusBlocked, msg: “flow reject check blocked”),否则表示通过返回nil
- ThrottlingChecker:目的是期望当token数超过了匀速排队的阈值时以排队的方式让上层等待或者sleep,而非直接丢弃。代码中的几个实现细节:
- 此处匀速排队的意思是指StatIntervalInMs/Threshold来计算每一个token的速度,而非StatIntervalInMs时间内通过Threshold后其余数据排队。比如设置qps为5(StatIntervalInMs:1000, Threshold为5),那么匀速就是指每200ms只允许通过1次请求,如果两次请求的间隔时间小于200ms,那么会被立即要求排队,而非等到1000ms内的5个请求之后。。
- 需要考虑并发场景,所以控制器维护了一个lastPassedTime的属性,用于记录已排队到的时间戳,记住更新、读取时需要原子操作。由于lastPassedTime即可反应当前的排队请求,所以ThrottlingChecker也不需要流量统计数据结构,仅需要更新lastPassedTime数据即可。
- 预估排队耗时无法精确,只能根据阈值threshHold和统计时长statIntervalInMs预估系统的处理速度,然后根据token数(batchCount)估算
- 允许排队时,返回特定TokenResult(state:ResultStatusShouldWait),供上层或者sentinel执行排队处理。根据是否指定最大排队耗时MaxQueueingTimeMs,区分两种情况。
- 不指定最大排队耗时,则直接返回给上层,由业务自行决定如何处理。
- 指定了最大排队耗时,怎在执行规则匹配(资源访问)时会Sleep一段时间,保障上层调用能够匀速处理。—— 注意这里可能会导致上层处理被临时block一段时间,导致服务内存的堆积。
func (c *ThrottlingChecker) DoCheck(_ base.StatNode, batchCount uint32, threshold float64) *base.TokenResult { |
除了Warmup的计算逻辑稍微麻烦点外,阈值计算器和行为控制器的逻辑都比较简单且独立。可以直接看相关代码。
除了以上部分,稍复杂的部分就是流量统计数结构的设计了。此部分单独介绍。
流量统计数据结构
流量统计数据结构构建其实也是初始化规则的一部分,因流程比较复杂,此处单独抽取介绍。
在构造流量控制器的最后一步就是生成流量统计结构standaloneStatistic(流程见generateStatFor),并将其绑定到流量控制器用于读写流量token计数。核心数据结构是使用滑动窗口来实现,下面介绍几个核心数据结构。
流量统计的整体结构是基于滑动窗口来实现的,为了将流控实现足够均匀,将滑动窗口拆分多尽量细致的多个bucket,每个bucket只记录很短一段时间的数据。如果需要统计一段周期内的流量,只需要从滑动窗口中取出一段周期内的bucket数据累加即可。以周期周期1s为例,如果滑动窗口的格子只有1s,那么可能出现[500ms, 1500ms]内流量大于Threshold的情况,但是如果将滑动窗口拆分为500ms个小格子,那么统计1s的流量时就能做到足够精确。
滑动窗口
Bucket以及LeapArray定义:
type BucketWrap struct { |
LeapArray为最底层的滑动窗口实现。窗口的时间长度以及BucketWrap个数由参数控制。
BucketWrap:即为滑动窗口的最小节点,但是没有直接存储统计数据,而是存储了为保证其原子操作的atomic.Value。其真实的数据由上层generator生成并填充。
BucketWrapArray:构造了一个以BucketWrap为节点的时间轮,并初始化每个节点。考虑到每轮周期完毕后BucketWrap会被复用,所有在其中记录了每个节点对应的时间戳,当发现数据已过期时Reset即可得到一个新的BucketWrap。
LeapArray:BucketWrapArray上层的封装,提供了根据时间戳定位BucketWrap等能力,需要考虑并发访问、节点过期更新等场景。每次访问滑动窗口时可以根据时间戳与滑动窗口长度(ms)取模就可以定位到对应的BucketWrap。下面为根据当前时间戳获取bucket以及一段周期内数据的处理流程。
// 时间与滑动窗口长度取模,定位bucket index |
BucketLeapArray:在LeapArray之上的滑动窗口封装,可以理解为LeapArray的API层。负责将滑动窗口的实现以及Bucket内容generator的实现关联,对外提供一个带数据存储的完整滑动窗口实现。
type BucketLeapArray struct { |
MetricBucket:存储在bucket中的统计结构体,格式为分事件存储的数据累加值,以及两个仅需记录最大、最小的。
// There are five events to record |
可见同一资源各种功能的数据是存储在一起的,包括流量控制、并发隔离等。
上层可以直接使用BucketLeapArray来统计数据,但是计算会比较繁琐,所以继续封装了一层SlidingWindowMetric对象,来实现周期内的minRT、maxConcurrency等的读取操作。
type SlidingWindowMetric struct { |
需要注意的是SlidingWindow是一个虚拟结构,内部关联了滑动窗口对象,SlidingWindow只可读,而且读的数据是通过聚合各个bucket节点数据得到的。
资源全局滑动窗口
规则根据滑动窗口使用方式上,存在两种类型的滑动窗口:
- 规则自己的滑动窗口,由该规则独享。其长度以及bucket数目由规则的StatIntervalInMs参数以及计算出来sampleCount参数决定。
- 资源下的共享滑动窗口,其长度以及bucket数目由全局配置globalStatisticSampleCountTotal、globalStatisticIntervalMsTotal参数决定。
理论上每条Rule维护自己的时间窗是最为简单的,这样可以保持数据之间相互隔离。但是维持时间窗一个比较重的逻辑,需要维持计数的准确性。如果存在10条规则,那么每个规则的时间窗都需要进行对应的bucket计数加1操作。于是出现了资源下的共享滑动窗口(也叫全局滑动窗口)的概念。
数据统计结构standaloneStatistic:
type standaloneStatistic struct { |
资源访问
入口:Entry
使用责任链模式,完成各种功能的check。
// Sentinel 本质是一个流控包,不仅提供了限流功能,还提供了众多其他诸如自适应流量保护、熔断降级、冷启动、全局流量 Metrics 结果等功能流控组件, |
总结
sentinel的功能很丰富,存在各种语言的版本,实现上也非常注意性能相关的细节优化。在一些并发逻辑的处理上也值得学习。如果要将其性能发挥到最大的空间,还需要进一步自信分析各种参数配置,包括滑动窗口的配置、定制SlotChain等。